WebNN is an emerging W3C web standard that brings high-performance neural network inference to web applications. It provides a low-level, hardware-agnostic JavaScript API for building and executing ML models in the browser, tapping into on-device accelerators (GPUs, NPUs, or CPU SIMD) for fast inference. By leveraging underlying APIs like DirectML on Windows or Core ML on macOS, WebNN lets developers exploit native ML hardware optimizations without writing platform-specific code . Crucially, WebNN enables features like real-time video analysis, face/speech recognition, and on-device image generation while keeping user data local . As of late 2025 the WebNN spec is a W3C Candidate Recommendation , meaning it has broad agreement and is on track to become an official recommendation once multiple interoperable implementations exist. It hasn’t been released yet, but it will be soon.
Purpose
- Low Latency
- Privacy Preserving Inference
Design Goals and Principles
WebNN’s design is minimal, secure, and future-proof. It exposes only the essential building blocks of neural nets (tensors, operators, and graphs) in a graph-centric model. The API treats model inference as a dataflow graph: developers use an MLGraphBuilder to define the graph structure (inputs, ops, outputs) and then compile/execute it via an MLContext. By separating graph construction (a pure data-definition phase) from execution, WebNN “minimizes the attack surface” – no code runs until the developer explicitly dispatches the compiled graph . In fact, the spec notes that the builder “doesn’t execute anything, only constructs data,” so security hardening can focus on the single execution step . WebNN also favors simplicity and extensibility. The specification advises: “When in doubt, leave it out: keep the API surface as small as possible” and “keep the API free of implementation details that might inhibit future evolution” . High-level convenience functions (e.g. fused activations) are defined in terms of lower-level primitives, allowing them to be replaced or polyfilled without breaking compatibility . This means WebNN can evolve – e.g. deprecate or optimize operators – while providing a stable minimal core. The result is a clean, low-level API akin to WebGPU’s compute interface, but specialized for neural networks. WebNN runs only in secure contexts (TLS pages) and obeys browser permission policies, ensuring that ML hardware isn’t misused by untrusted scripts.
WebNN API Surface
At its core, WebNN exposes these key interfaces in JavaScript:
- navigator.ml and MLContext – Entry points. A web app calls await navigator.ml.createContext({powerPreference}) to get an MLContext bound to the device (CPU/GPU/NPU) it chooses. An optional power hint (‘high-performance’ vs ‘low-power’) can influence device selection. The context encapsulates the execution environment.
- MLGraphBuilder – Used to construct the computational graph. The builder provides methods for tensor operations (e.g. add(), conv2d(), relu(), etc.). Example primitives include matrix multiply (gemm), convolutions, pooling, activation functions, and more. Inputs are declared via builder.input(name, {dataType, shape}), weights via builder.constant, etc. The builder only defines nodes and edges; it does not execute.
- MLGraph – After defining the graph, the developer calls await builder.build({outputName: outputOperand}) to compile it into an immutable MLGraph object (representing the compiled model). Graph compilation optimizes operations (e.g. fusing layers) and readies the model for execution.
- MLTensor and TypedArray – Data is passed in/out via multi-dimensional tensors. A tensor is just a typed-array buffer plus metadata. For inference, the app creates input/output tensors (e.g. using MLContext.createTensor()) and binds them to the graph.
- Execution (dispatch) – Finally, await context.dispatch(graph, inputs, outputs) runs the model on the chosen backend. It returns a Promise that resolves when computation completes. After dispatch, output tensors contain the results.
Below is a simplified code example adapted from the spec, building and running a tiny graph (computing C = 0.2*A + B): Note: You will have to enable webnn in chrome://flags (2025-11-21) It will eventually be available without enabling when webnn is stable
const context = await navigator.ml.createContext();
const builder = new MLGraphBuilder(context);
// Define inputs
const A = builder.input("A", {
dataType: "float32",
shape: [2, 2]
});
const B = builder.input("B", {
dataType: "float32",
shape: [2, 2]
});
// Constant tensor
const weight = builder.constant(
{ dataType: "float32", shape: [2, 2] },
new Float32Array([0.2, 0.2, 0.2, 0.2])
);
const C = builder.add(builder.mul(A, weight), B);
const graph = await builder.build({ C });
// Create input tensors
const inputTensorA = await context.createTensor(
{ dataType: "float32", shape: [2, 2] },
new Float32Array([1, 1, 1, 1])
);
const inputTensorB = await context.createTensor(
{ dataType: "float32", shape: [2, 2] },
new Float32Array([2, 2, 2, 2])
);
// Create persistent output tensor
const outputTensorC = await context.createTensor({
dataType: "float32",
shape: [2, 2]
});
// Execute graph
await context.dispatch(
graph,
{ A: inputTensorA, B: inputTensorB },
{ C: outputTensorC }
);
// Read result using the spec method
const result = new Float32Array(4);
console.log(result);This snippet demonstrates the typical graph-building workflow (inputs, constants, operations, build, then dispatch) . (The spec contains many such examples showing how to compose operators.) The MLGraphBuilder API supports dozens of common neural network layers (convolutions, poolings, matrix multiplies, LSTM, softmax, and more), grouped into families for consistency. The API works only in promise-based async form (no blocking calls), reflecting modern web design.
flowchart
WebApp[Web App - JavaScript] -->|navigator.ml| WebNNAPI[WebNN API]
WebNNAPI --> MLContext[MLContext]
MLContext -->|new GraphBuilder| Builder[MLGraphBuilder]
Builder -->|define ops| GraphDef[Model Graph - uncompiled]
GraphDef -->|build| CompiledGraph[Compiled MLGraph]
MLContext -->|dispatch| Execution[Execute Graph on Device]
Execution --> Output[Output MLTensors]
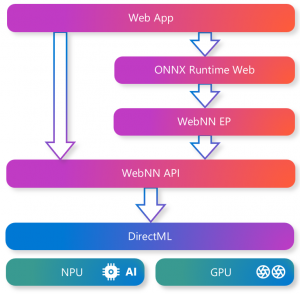
Figure: High-level architecture of WebNN. The browser exposes the WebNN API (navigator.ml) to JS, builds and compiles a model graph, and dispatches it to the WebNN Service. The service routes execution to platform-specific backends (DirectML on Windows, CoreML on Apple, ONNX Runtime, etc.), which in turn execute on the actual hardware.
On Windows, Microsoft has tightly integrated WebNN with DirectML. In fact, the Windows WebNN Developer Preview (used by Edge Canary) is built on DirectML and ONNX Runtime Web. Microsoft documentation emphasizes:
“WebNN is a web standard that defines how to run machine learning models in the browser, using the hardware acceleration of your local device’s GPU or NPU. One of the backends WebNN can use is DirectML, which provides performant, cross-hardware ML acceleration across Windows devices.” .
Hardware vendors (AMD, Intel, NVIDIA) are collaborating on drivers for DirectML to ensure WebNN works across GPUs and NPUs. A recent blog announced a preview in Edge: WebNN can now run ONNX models with DirectML acceleration in the browser, unlocking GPU/AI hardware without platform-specific code . In practice, this means a web app can simply load an ONNX or TensorFlow model and run it via WebNN, leveraging native DirectML performance under the hood.
Use Cases and Benefits
By enabling efficient on-device inference, WebNN unlocks many web app scenarios:
- Real-time media processing: WebNN lets browsers run vision and audio models locally. For example, live object/person detection, semantic segmentation, or face recognition on camera streams (for video calls or AR) become feasible with low latency. Similarly, speech recognition and noise suppression can run in-browser on audio input. Microsoft explicitly cites use cases like person/face detection, style transfer, super-resolution, image captioning, machine translation, and noise suppression as targets for WebNN .
- Generative AI: Emerging generative models (text, images, audio) often require significant compute. Running them on-device via WebNN means interactive demos (e.g. image inpainting, text autocomplete) can work without server calls. The W3C spec even discusses “text-to-image” inpainting and outpainting use cases . By keeping models local, WebNN preserves user privacy for sensitive inputs.
- Offline and low-bandwidth: Because computation is local, WebNN enables AI features in offline-first apps (e.g. on-device NLP, gesture recognition, handwriting recognition) where no network is needed . This boosts availability and reduces cloud costs. WebNN’s own documentation highlights “high availability” – once models are cached, no network is required – and “low cost” (no server maintenance) .
- Framework Backend: WebNN is designed to be a backend for JS ML libraries. For instance, TensorFlow.js and ONNX Runtime Web can use WebNN under the hood. Ping Yu (TensorFlow’s TL) notes that giving frameworks access to native ML accelerators “can greatly improve model execution efficiency” . In practice, ONNX Runtime Web includes a WebNN execution provider, meaning you can run ONNX models with minimal changes to code . This allows existing web ML code to benefit from hardware acceleration transparently.
Performance Insights
Early results and benchmarks show dramatic speed-ups when using WebNN compared to CPU or polyfill approaches. The WebMachineLearning group reports “tremendous power & performance improvements” in WebNN workloads . For example, a W3C TPAC demo compared a native WebNN implementation (using Intel’s OpenVINO) against a TensorFlow.js polyfill. Across image-classification, segmentation, and detection models (MobileNet, ResNet, YOLO, etc.), the native WebNN version achieved much higher FPS than the WebGL/WASM polyfill . In practical terms, WebNN can run the same model several times faster, enabling smooth real-time ML in scenarios where JS frameworks struggle. Similarly, on Windows DirectML, Microsoft’s testing shows multi-fold gains. By leveraging GPU shaders and tensor cores via DirectML, WebNN-based inference can execute models (e.g. MobileNet, Whisper, Stable Diffusion) up to orders of magnitude faster than a pure-CPU fallback. This makes interactive applications (like image editing or video apps) much more responsive. Note that precise performance depends on hardware: a high-end GPU or dedicated NPU will outperform integrated CPU compute. But crucially, WebNN lets the browser pick the best available accelerator, yielding consistently better throughput than generic WebGL/WebAssembly paths. Besides speed, hardware execution can also improve energy efficiency for large models, as dedicated AI units often consume less power per operation than a CPU. This can translate to smoother performance on battery-powered devices. (Developers can hint low-power preference if needed.)
Comparison with Alternatives
WebNN is part of a growing ecosystem of browser ML solutions. It differs from alternatives in several ways:
- WebGPU: WebGPU is a general-purpose graphics and compute API in browsers. While powerful, using WebGPU for ML requires manually writing shader programs (WGSL) for each neural operation or relying on third-party libraries. WebNN sits a level above WebGPU: it provides ready-made neural operations (conv, matmul, etc.) so developers don’t need to write GPU code. Internally, WebNN implementations may even use WebGPU under the hood (as a hardware layer), but WebNN spares the developer from that complexity. In short, WebGPU is like Assembly for GPU compute, whereas WebNN is a domain-specific ML API.
- TensorFlow.js: TensorFlow.js offers high-level model-building (Layers, Sequential APIs) and can run in-browser via WebGL or WASM. It’s user-friendly and has a large ecosystem, but it’s a full framework with sizable bundle and slower backends. By contrast, WebNN is minimal and doesn’t include any model architecture or training code – just inference ops. Using WebNN (directly or via ONNX Runtime) can avoid bundling large ML libraries. As one analysis notes, “Using WebNN allows teams to avoid bundling large model runtimes like TensorFlow.js… This reduces bundle size, improves startup time, and makes the client more responsive” . In other words, WebNN plus ONNX/TF models gives equivalent inference power with much smaller JS overhead. However, TensorFlow.js is more mature for training and model building in JS, whereas WebNN is inference-only.
- ONNX.js / ONNX Runtime: ONNX.js was an earlier effort to run ONNX models in the browser (using WebGL/WASM). It has largely been supplanted by ONNX Runtime Web, which now integrates WebNN. The new ONNX Runtime Web can use WebNN for acceleration (falling back to WASM otherwise). In effect, WebNN has become the hardware API that ONNX models target on the web. Compared to ONNX.js, which was a standalone JS library, WebNN as a browser API is standardized and can leverage more direct hardware paths.
Below is a rough comparison summary:
- Performance: WebNN (on GPU/accelerator) ≫ TensorFlow.js (WebGL) ≈ WASM. WebGPU can match WebNN if equally optimized, but lacks built-in ML ops.
- Portability: WebNN runs anywhere the browser implements it (Windows, macOS, etc.). TF.js runs in all browsers too, but may use CPU or WebGL only. ONNX/ORT with WebNN shares similar portability as long as WebNN is supported.
- Developer Experience: WebNN requires a lower-level graph construction (less user-friendly than TF.js layers). However, frameworks can abstract WebNN usage (e.g. ONNX Runtime Web or wrappers). WebNN’s API is straightforward for defining inference graphs. Compared to writing WebGPU shaders, it’s much easier. And because it’s standardized, once WebNN is available in a browser, developers don’t need separate engine downloads or heavy JS libraries.
Code Example: Image Classification with WebNN
As a concrete example, consider running an ONNX image-classification model (e.g. MobileNet) with WebNN. Using ONNX Runtime Web, one might write:
import {InferenceSession, Tensor} from 'onnxruntime-web';
// Load a model (bundle or fetch)
const session = await InferenceSession.create('mobilenetv2.onnx', {executionProviders: ['webnn']});
const imageTensor = Tensor.from(imageData); // prepare input tensor
const feeds = {input: imageTensor};
const outputMap = await session.run(feeds);
const outputTensor = outputMap.output;
console.log(outputTensor.data); // probabilitiesBehind the scenes, ONNX Runtime Web will compile the ONNX graph into WebNN operations and dispatch them to the best hardware via DirectML (on Windows) or CoreML (on macOS) if available . The developer’s code doesn’t change between desktop and mobile; the browser handles the implementation details. This contrasts with, say, using WebGL shaders by hand: WebNN/ORT handles operator-level optimizations automatically.
Performance Benchmarks
While formal benchmark suites are still emerging, available demos suggest WebNN dramatically outperforms browser ML polyfills. In one demo, native WebNN using Intel’s OpenVINO backend achieved several-fold higher FPS on models like MobileNet and TinyYOLO compared to a TensorFlow.js polyfill (WebGL/WASM) on the same machine . In another case, using WebNN on an Intel GPU showed orders-of-magnitude faster inference times than CPU-only runs. In summary, WebNN enables hardware-accelerated inference in the browser with performance close to native apps. Its priority is inference (not training) and it leverages optimized libraries like DirectML, so it achieves much higher throughput than general-purpose WebGL compute. As implementations mature, we expect to see benchmark data quantifying gains on various tasks. For now, the rule of thumb is: if TensorFlow.js is too slow for your model, try WebNN/ORT on a compatible browser – you’ll likely see big speedups.
Conclusion
WebNN represents a major step towards a web platform that is AI-capable by default. By providing a standard, low-level ML API, it allows web developers to build sophisticated on-device AI features — from computer vision to speech and generative models — with industry-grade performance and privacy. Its design carefully balances minimalism and flexibility, enabling future evolution while keeping the API small and secure . With major browsers (Chrome/Edge) already shipping WebNN support (especially on Windows and Apple hardware), the stage is set for web frameworks and apps to adopt it. In the near future, we anticipate WebNN being as ubiquitous on the web as WebGL or WebRTC – a key enabler for the next generation of intelligent web experiences.
References
- https://www.w3.org/TR/webnn/
- https://github.com/webmachinelearning/webnn
- https://learn.microsoft.com/en-us/windows/ai/directml/webnn-overview
- https://chromium.googlesource.com/chromium/src/+/lkgr/services/webnn/
- https://blogs.windows.com/windowsdeveloper/2024/05/24/introducing-the-webnn-developer-preview-with-directml/#:~:text=WebNN%20is%20a%20web%20standard,performance%2C%20and%20reliability%20of%20DirectML
- https://webmachinelearning.github.io/webnn-intro/#:~:text=Low%20Latency%20In,cases%20with%20local%20media%20sources
- https://medium.com/rethinking-the-client-a-new-era-of-modular/ai-in-the-runtime-why-webnn-changes-everything-70494a3cf524
- https://github.com/webmachinelearning/webnn/blob/main/explainer.md